
O verdadeiro custo de um LLM
Indo além de input e output tokens.

Quando vamos analisar um LLM, é tentador avaliá-lo pelo preço por token. Isso faz sentido: esse é valor que cada provedor escolhe quando disponibiliza um modelo para o público. Hoje vamos discutir por que essa métrica é importante, mas não suficiente.
A matemática dos tokens
Antes de mais nada, precisamos entender o que é um token. De forma bem simplificada, um token é um “pedacinho de texto” que o modelo enxerga: pode ser uma palavra inteira, parte de uma palavra ou até um sinal de pontuação.
Modelos como o GPT funcionam de forma preditiva: eles recebem uma sequência de tokens e calculam, a cada passo, qual é o próximo token mais provável dado tudo o que veio antes. Por exemplo, se os tokens até agora representam a palavra Hello, a probabilidade de que o próximo seja World é relativamente alta. Repetindo esse processo, token após token, o modelo vai montando o texto, ou seja, o output que é retornado pela IA.
Esse processo é chamado de inferência, ou seja, o ato do modelo de processar o input e retornar um output. Uma vez que gerar tokens é tipicamente mais caro que somente ler os tokens, divide-se o custo de um modelo entre input e output tokens. Em outras palavras, quanto custa enviar um “pedaço de texto” para o modelo processar e quanto custa cada “pedaço de texto” gerado.
Naturalmente os provedores competem entre si não só em capacidade do modelo, mas também em preço e velocidade. É por isso que existem tantas opções: muitos deles são treinados para tarefas específicas, ou possuem um conjunto de características que favorece uma determinada atividade. Por exemplo, a programação favorece os modelos com maior capacidade computacional. Porém, quando se executa uma tarefa de classificação, é normal sacrificar a acurácia em favor do preço e velocidade.
Um exemplo concreto: recentemente precisei analisar um dataset de 10.000 fotos de perfil e identificar se havia uma pessoa. Como esse é um problema fácil de classificação (pois é comum encontrar na base de treino do modelo fotos de pessoas), optei por um modelo mais barato e rápido. No caso, utilizei o GPT 4.1 Nano, que custa $0.10 por milhão de input tokens, e $0.40 por milhão de output tokens. Para referência, o modelo GPT 5.1 tradicional custa $1.25/M e $10/M por input e output tokens respectivamente. Ou seja, embora os dois modelos sejam capazes de resolver o problema, um deles custaria ~15x a mais que o outro!
Escolher o modelo adequado é como escolher o meio de transporte adequado para ir do ponto A ao ponto B. Nem sempre a escolha é óbvia, e o contexto importa bastante. Estou com pressa? Está trânsito? Está chovendo? A distância é grande? É estrada ou cidade? Voltaremos a essa analogia em breve.
Note que outra variável bem importante na escolha do modelo é qual o formato do input e do output. Por exemplo, trabalhos de sumarização tendem a gastar muito mais input do que output tokens. Mas se você pedir para que o LLM gere um relatório ou um texto, gastará mais output tokens. No exemplo da classificação, uma boa prática é definir um response schema, forçando o modelo a obedecer um formato de output. Esse foi o custo médio por imagem gerado pelo script de classificação:
Per Image:
- Input tokens: ~990 (prompt + image)
- Output tokens: ~44 (JSON response with description)
Veja que excelente economia! Enquanto o output token custa 4x mais que o input token, o problema foi modelado de forma que o LLM retornasse ~20x menos tokens, tornando o processo bem barato (fazendo as contas, o custo para processar as 10.000 imagens ficou pouco acima de $1).
Otimizando seu prompt
Existem outras formas de barateamento, principalmente quando o LLM é utilizado numa conversa (provavelmente a aplicação mais tradicional desse tipo de IA). Imagine a seguinte interação:
(0) System Prompt: Você é um assistente cujo objetivo é auxiliar os clientes a gerenciarem suas contas.
(1) Usuário: Olá
(2) IA: Olá, como posso ajudar?
(3) Usuário: Gostaria de cancelar o meu plano.
(4) IA: Que pena! Para podermos dar continuidade ao seu pedido, por favor confirme o seu email e telefone.
Imagine que você é o desenvolvedor responsável por criar esse chatbot utilizando uma API (como por exemplo a API da OpenAI). A primeira interação, marcada com (1) é uma requisição para o servidor que utilizará o modelo selecionado (ex: gpt-5.1-nano) e saberá quem cobrar através de uma chave de API associada a sua conta. Nessa primeira requisição, você enviará o conjunto System Prompt + Mensagem 1 como input, que será tokenizado (uma forma de verificar quantos tokens serão cobrados é através de uma biblioteca como o tiktoken).
O modelo processará essa requisição e responderá com (2). Você então mostra a mensagem para o usuário, que envia a mensagem (3). O que acontece agora? Não adianta só enviar (3), mas sim todo o histórico até o momento atual: (0) + (1) + (2) + (3), que serão tokenizados e enviados para o modelo, que processará e retornará (4). E assim a conversa segue.
Note que a cada iteração é enviado um conjunto significativo de tokens já processados. Uma técnica comum é cacheá-los, ou seja, salvá-los para que não precisem ser processados novamente. Cached input tokens são tipicamente entre 4-10x mais baratos que input tokens normals (o site llm-prices.com é uma boa fonte de conferência). No novo GPT 5.1, o prompt pode ser cacheado por até 24h (!) o que é excelente para reduzir custos de qualquer aplicação que dependa dessa interação entre usuário e modelo.
A eficiência por token
Já sabemos que a modelagem de custo de um LLM depende dessas 3 variáveis que são controladas pelo provedor: input token, output token e cached input token. Mas eles ainda não contam a história toda.
LLMs são modelos estocásticos, o que significa que nem sempre darão a mesma resposta. Além disso, como cada modelo tem a sua própria capacidade, é possível que uma tarefa seja realizada em apenas 1 interação por uma determinada IA, mas em 5 por outra. Assim, mais do que analisar o preço de cada token, deve-se analisar a eficiência por token de cada modelo.
Considere dois modelos que recebem a mesma tarefa. Acertar a resposta é apenas uma das métricas: a outra seria custo e velocidade. Voltemos ao exemplo dos meios de transporte: ir do ponto A para o B é importante, mas a que custo e demorando quanto tempo? Uma Fiat Uno e um Audi A5 conseguem te levar em qualquer trajeto, mas o consumo, o km/L é bem diferente.
Um problema de se medir isso em tarefas de programação é que virtualmente todo projeto é diferente: tem seu próprio contexto, arquivos, stack, etc. A variabilidade é infinita – o que torna a padronização difícil. Uma alternativa é eleger alguns benchmarks, “provas” específicas que cada modelo precisa realizar, medindo a acurácia, o custo e o tempo. O exemplo abaixo é do SWE-bench, um benchmark voltado para problemas de engenharia de software:
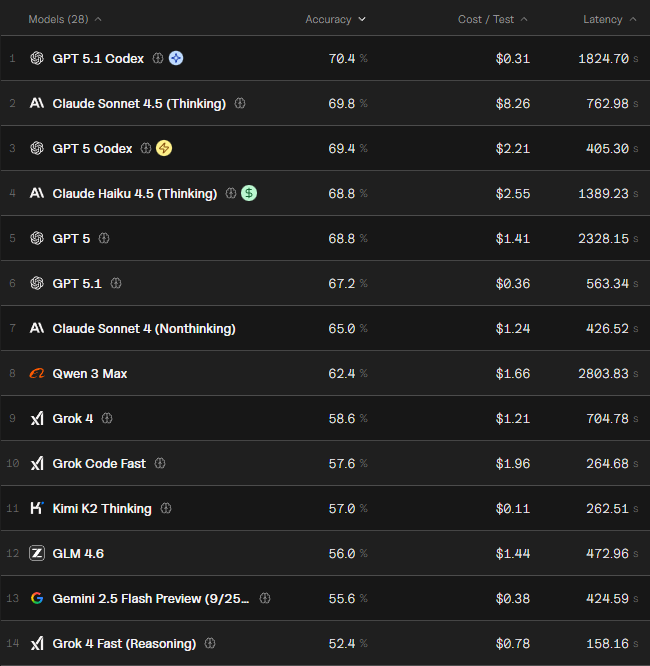
Em que pese a fragilidade inerente a todos os benchmarks, e sem fazer juízo de valor sobre a acurácia desse exemplo em particular, é necessário olhar o custo efetivo para a realização da tarefa. Embora virtualmente empatados, a mesma tarefa custa 26x menos com o GPT 5.1 Codex do que com o Sonnet 4.5. Se olhássemos apenas para os tokens, essa diferença seria apenas ~2x. Mas a capacidade do modelo na missão específica (“quão adequado o carro é para o terreno”) influencia tanto ou mais.
No dia a dia essa diferença fica ainda mais visível. Modelos que tem maior capacidade de abstração conseguem navegar pela codebase (ou seja, agentes), e conseguirão preencher o contexto com as informações necessárias. Enquanto isso tende a aumentar a lentidão da resposta, a acurácia quase sempre irá compensar (essa foi a razão pela qual troquei o Claude Code pelo Codex). Quanto mais intervenções você precisar fazer, mais caro fica a execução da tarefa. Voltando às analogias com carro, é como querer economizar gasolina abastecendo apenas meio tanque: você só fará mais viagens ao posto, gastando mais combustível (tokens) do que o necessário.
O custo final
Embora a preferência por um modelo possa (e deva!) ser particular, o custo associado pode ser objetivamente medido através do preço por token e pela eficiência por token. No geral, não só uma maior eficiência será melhor para o seu bolso, mas quase sempre significará um melhor gerenciamento de contexto, o que evita que programadores atinjam os inevitáveis rate limits (ver A economia da IA), e prolonga a acurácia do modelo antes que sua capacidade se deteriore (normal à medida que muita informação vai sendo adicionada e uma compactação se torne necessária).
Evidentemente a eficiência também ajuda a desmascarar modelos que no papel são baratos mas terminam saindo caros, pois a quantidade de interações é tão maior que simplesmente não compensa utilizá-lo para a tarefa (de nada adianta percorrer um longo trecho de bicicleta sob a justificativa de que é mais barato do que o carro mas terminar perdendo o compromisso).
Com a competição entre os provedores – o que tende a levar a um muito bem vindo barateamento dos preços por tokens – prevejo que cada vez mais será importante levantar esse ponto: que o modelo é mais barato conseguimos ver, mas será que ele é mais eficiente? Somente o tempo e o uso nos mais variados contextos poderá dar a resposta.
Incrível, muito obrigada por este artigo. Clareou muita coisa por aqui! Já estou assinando, abraço!